
تعتبر عملية اتخاذ القرارات عملية معقدة تشوبها عوامل كثيرة. وفي غالب الأحيان، يضطر الإنسان إلى اتخاذ قراراته في أوضاع غامضة (Uncertainties) حيث لا يكون متأكداً من تبعات الخيارات المتاحة له. لذا فإن من الأهمية بمكان أن تكون قراراته مبنية على معطيات مقنعة (Informed decisions) لتكون هذه القرارت مبررة (Rational) وأقرب للصواب.
ولأن نظرية الاحتمالات هي أكثر نظرية استخدمت لتقدير غموض الأحداث، فإنها النظرية الأكثر شيوعاً في تمثيل عملية اتخاذ القرارات في الأوضاع الغامضة (Decisions under uncertainty). ولتمثيل غموض الأحداث وترابطها، ظهرت النماذج الشبكية الاحتمالية (Probabilistic Graphical Models)، كمزيج بين نظرية الشبكات (Graph theory) ونظرية الاحتمالات (Probability theory)، والتي تستخدم لمحاكات عمليات الاستنتاج والتوقع. وهذا يساهم في بناء أنظمة تساعد في عملية دعم اتخاذ القرارات وفق المعطيات الموجودة.
وسأقوم من خلال هذه المقالة بشرح مبسط لأبرز المفاهيم في النماذج الشبكية الاحتمالية متبنياً العرض المنطقي، مبتعداً قدر الإمكان عن العرض الرياضي الجبري، على أمل أن تكون المقالة مناسبة للقراء من مختلف المشارب. ولأن التعليم يعتبر من أهم القطاعات التي تساهم في رقي المجتمعات (بل هو القطاع الأبرز من وجهة نظري)، فإن عرض المفاهيم والأمثلة سيكون في سياق البيئة التعليمية. فمع وجود البيانات المستقاة من بيئة التعليم على شكل إلكتروني، فإن تطوير برمجيات للاستفادة من هذه البيانات في محاكاة البيئات الحقيقة أو في التحليل أصبح ممكناً لحل كثير من المشاكل.
وسأقوم بداية بإعطاء نبذة مبسطة عن نظرية الاحتمالات. وسأشرح بشكل مبسط قدر الإمكان ترابط الأحداث واستقلالها من منظور احتمالي. وسأناقش بشكل سريع مفهومي الارتباط والسببية. وأود أن أنبه إلى أن الأحداث التي ستعطى في هذه المقالة ليست بالضرورة أحداثاً مطابقة للواقع بل هي فقط أحداث افتراضية لغرض الشرح وقد يكون الواقع مغايراً.
الاحتمالات
معنى كلمة “احتمال”
“احتمال أن أحصل على تقدير ممتاز في مادة التاريخ 0.7؟“. لو قال طالب لك هذه الجملة فماذا يعني بها؟
عندما نشير لاحتمال وقوع حدث ما، فهنالك تفسيران لكلمة “احتمال” يستخدمها الدارسون. وقبل نقاش هذين التفسيرين، أود بداية شرح مصطلح مرتبط بالحدث ألا وهو ما يعرف بالـ States of affairs، والذي يمكن اعتباره على أنه مختلف الحالات التي يحدث فيها الحدث (أي الحالات التي تجعل من الحدث واقعاً) في ظل ثبات الظروف أو المعطيات الأخرى. فبالعودة إلى تفسيري كلمة “احتمال” فإن التفسير الأول، وهو ما يسمى بالـ (Frequentist)، يقضي بأنه في ظروف ثابتة ومحددة، فإن احتمال حدث ما هو الرقم الذي تقترب له نسبة الحالات التي يحدث فيها الحدث إلى مجموع الحالات كلها عندما تتكرر نفس الظروف أو المعطيات بعدد كبير. وبالعودة للجملة السابقة “احتمال أن أحصل على تقدير ممتاز في مادة التاريخ 0.7“، فإن هذا يعني أنه لو درس الطالب مادة التاريخ تحت نفس الظروف 100 مرة مثلا، فإن عدد الحالات التي يحصل فيها على تقدير ممتاز يكون قريباً من 70 حالة من أصل الـ 100 حالة. وفي حالة زيادة عدد مرات الدراسة في نفس الظروف، فإن هذه النسبة تقترب أكثر من الـ 0.7. أما التفسير الآخر لكلمة “احتمال” والتي سأتبناها في هذه المقالة، هو ما يعرف بالــ Bayesian interpretation of probability، وهو أن احتمال حدث ما هو درجة الاعتقاد (Degree of belief) بأن حالة من الحالات التي يقع فيها الحدث ستحدث (أياً كان مبرر هذا الاعتقاد). فقول “احتمال أن أحصل على تقدير ممتاز في مادة التاريخ 0.7” يعني أن لدي اعتقاد بنسبة 70% من أن حالة من الحالات التي تمكنني من الحصول على تقدير ممتاز في مادة التاريخ ستحدث، دون الحاجة لاعتبار تكرار الظروف أو المعطيات. ويلاحظ أن هذا التفسير لكلمة “احتمال” شخصي وغير محدد (Subjective) بينما التفسير الأول ثابت لايختلف من شخص إلى آخر (Objective). ولكن في نفس الوقت فإن التفسير الأول والذي يعتمد على تكرار الظروف يواجه بعض الإشكالات في كثير من الأحداث. فلو أخذنا الحدث في المثال السابق، فإن الطالب عادة لا يدرس المادة سوى مرة واحدة تحت نفس الظروف. فلو درسها مرتين فإن الظروف في المرة الثانية تكون مغايرة عنها في المرة الأولى (مثلاً في المرة الثانية تكون خلفيته المعرفية في المادة أعلى منها في المرة الأولى غالباً)، وبالتالي يكون الحدثان هنا مختلفين. والخلاف في تفسير معنى “احتمال” فلسفي وعميق لذا سأكتفي بما ذكرت.
سأستخدم في هذه المقالة الأحرف الإنجليزية الصغيرة للإشارة إلى الأحداث اختصاراً، فمثلاً:

ولأي حدث 


دع 



فإن:

لنشير إلى عامل الاقتران المنطقي “و” بـ 
مثال: الطالب س ينجح في مادة التاريخ
، وبعامل التخيير المنطقي “أو” بــ 
مثال: الطالب س ينجح في مادة التاريخ
(الطالب س ينجح في مادة التاريخ أو أنه لا يحب المادة. ملاحظة: هذه الجملة تعني أنه بالإمكان أن ينجح الطالب وهو لا يحب المادة، ويمكن الرجوع إلى جدول الصواب للعامل “أو”).
يمكن بديهياً استنتاج التالي لأي حدث 


(احتمال الحدث ونقيضه يساوي 0، إذ أنه لا يمكن أن يحدث النقيضان)

(احتمال الحدث أو نقيضه يساوي 1، إذ أنه من المؤكد إما أن يحدث الحدث أو نقيضه)
ارتباط الأحداث واستقلالها
دعنا بداية نستخدم الصيغة:

لنعني قيمة احتمال وقوع حدث 

يعني أن معرفتنا بوقوع

مثال:


لو سألنا معلماً عن احتمال تدني تقدير طالب لديه وأعطانا قيمة معينة، ثم علم فيما بعد أن حصة الرياضة تغير موعدها من الفترة الصباحية إلى الظهيرة، ثم عاودنا سؤاله عن احتمال حصول نفس الطالب على تقدير متدن بعد معرفته بالحدث (في ظل عدم تغير الظروف الأخرى) لأجاب بنفس الإجابة السابقة. فلا تغير المعلومة التي حصل عليها اعتقاده بالحدث
أما إن كانت معرفتنا بــ

فإن اعتقادنا بوقوع

ما ينطبق على حدثين من الارتباط والاستقلال ينطبق على نقيضيهما:

استقلال حدثين بمعرفة أحداث أخرى
بالعودة إلى المثال السابق:
وكما ذكرنا سابقا أن 

فما هو احتمال 





والفائدة هنا هي أن استقلالية الأحداث واحتمالاتها قابلة للتغير بعد ورود معلومات عن الأحداث الأخرى. فزيادة البيانات كفيل بتغيير تقييمنا لاحتمالات الأحداث المراد فحصها وهذا ما يعرف بــ (Belief updating). لذا، ففي نظم التحليل ودعم اتخاذ القرارات، وفي حالة وجود أحداث كثيرة تحيط بالحدث الذي نريد تحليله أو اتخاذ قرار بشأنه، تبرز أهمية معرفة علاقات هذه الأحداث ببعضها وماهي الأحداث المستقلة وفق المعطيات التي لدينا. حيث يفيدنا ذلك في تمييز الأحداث التي نأخذها بعين الاعتبار من تلك التي لا تساهم في تقديم أية إضافة. ومن هذا المنطلق تبرز نظرية الشبكات (Graph theory) كأحد النظريات التي يمكن استخدامها لنمذجة الارتباط والاستقلال بين الأحداث. واستخدام نظرية الشبكات في نمذجة التوزيعات الاحتمالية (Probability distributions) هو ما يعرف بالنماذج الشبكية الاحتمالية (Probabilistic Graphical Models) والذي سيكون موضوع الجزء القادم من المقالة.
وقبل نهاية هذا الجزء، نشير إلى تعريف احتمال وقوع حدثين

والذي يعرف بقانون ضرب الاحتمالات. وكذلك يمكن تعريف احتمال حدوث أحد حدثين

والذي يعرف بقانون جمع الاحتمالات. ويلاحظ هنا طرح احتمال وقوع الحدثين معاً من مجموع احتمالي الحدثين. والسبب هو أنه في حالة أن الحدثين يمكن أن يقعا معاً (non-mutually exclusive)، فإن احتمال وقوعهما يحسب في كل من 






وعليه، إذا كنا نريد حساب احتمال حادثة ما، من دون أن نعرف وقوع حدث آخر، أو ربما لا يهمنا الحدث الآخر حيث أننا نريد معرفة احتمال الحدث المستهدف بغض النظر عن الأحداث الأخرى، فإننا نحسب احتمال حدوث الحدث المستهدف مع جميع أحوال الحدث الآخر، أي مع وقوع الحدث الآخر أو نقيضه، كالتالي:

وهذا يعرف بالاحتمال الهامشي (Marginal probability).
والقوانين أعلاه يمكن تعميمها لأكثر من حدثين، فاحتمال وقوع 


القانون أعلاه يعرف بقانون التسلسل للاحتمالات (chain rule of probability).
وباستخدام الرموز الإنجليزية الكبيرة للإشارة إلى متغير يسند إليه الحدث أو نقيضه:

فإن الاحتمال الهامشي لحدث ما 

وبالعودة إلى الجزء الأول من المقالة، وتحديداً لتعريف الحالات التي يحدث فيها الحدث أو الــ States of affairs، فإنها هنا في الاحتمال الهامشي، تتبين في مختلف القيم التي تأخذها المتغيرات الأخرى في حين أن الحدث 

النماذج الشبكية الاحتمالية
الشبكة (Graph) كتركيب تتكون من مجموعة من نقاط الالتقاء (Vertices)، وسأسميها هنا “الرؤوس”، ومجموعة من الروابط (Edges) بحيث أن كل رابط يربط بين رأسين. في المثال (a) أدناه 


والروابط إما أن تكون موجهة كما هو حال الرابط 






تستخدم الشبكات الموجهة والغير موجهة في تمثيل التوزيعات الاحتمالية بناءً على التطبيق وخصائص التوزيع الاحتمالي المراد استخدامه. في هذه المقالة سنركز فقط على التوزيعات الاحتمالية التي يمكن نمذجتها بالشبكات الموجهة الغير محتوية على دائرة والتي تعرف بــ Bayesian Network أو بــ Probabilistic Directed Acyclic Graph.
Bayesian Network
(ملاحظة: الاسم Bayesian هنا لا يعني أن الاحتمال يجب أن يفسر بالتفسير الثاني من التفسيرين الذين شرحناهما في بداية المقالة. إذ يمكن استخدام التفسير الأول في نمذجة الشبكة. الاسم في كلا الحالتين نسبة للعالم الإحصائي البريطاني “توماس بيس” ولكن الاصطلاحين مختلفان).
لنفترض أننا في إحدى البيئات التعليمية ونرغب في فهم الظواهر الموجودة في الشكل (a) أدناه. ولنفترض أننا حصلنا على القواعد الموجودة في (b) من خلال ملاحظات مشرفي البيئة التعليمية.

فإنه من خلال هذه القواعد، يمكن صياغة التوزيع الاحتمالي (Joint probability distribution) كالتالي (في حالة وجود أي إبهام، يمكن الرجوع للقانون التسلسلي للاحتمالات وقانون الاستقلال في الجزء السابق):

وبتمثيل هذا التوزيع الاحتمالي كشبكة موجهة نحصل على التالي:

والشبكة أعلاه تعرف بـ Bayesian Network وتمثل التوزيع الاحتمالي المعطى. ويتضح من هذه الشبكة أن أن وجود رابط بين متغيرين يعني وجود ارتباط بين الأحداث التي يمثلها هذان المتغيران. ولكن السؤال هنا هو كيف يمكن معرفة الاستقلال والارتباط بين المتغيرات الي لا ترتبط مباشرة مع بعضها؟ فمثلاً، لو أننا علمنا أن أحد الطلاب لديه قدرة منخفضة على الحفظ، أي 

و:

فإن كانت القيمتان متساويتين، فإن المتغيرين مستقلان عن بعضهما. وإن كانت القيمتان غير متساويتين، فإنهما مرتبطان ببعضهما.
ولكن القيام بمثل هذه الحسابات مكلف ومجهد. وأحد فوائد التمثيل الشبكي للتوزيع الاحتمالي هو معرفة ارتباط واستقلال الأحداث من دون الحاجة للقيام بهذه العمليات وذلك عن طريق بعض القواعد التي سنوضحها في الجزئين القادمين.
ارتباط واستقلال متغيرين يفصلهما رأس واحد
قبل وضع القاعدة العامة التي يمكن من خلالها قراءة الارتباط والاستقلال بين أي متغيرين في الــ Bayesian Network، بداية ندرس ارتباط واستقلال متغيرين يفصلهما رأس واحد فقط.
في حالة وجود متغيرين يفصلهما رأس واحد في الشبكة، فإن الرأس الفاصل لا يخلو من أن يكون على حالة من ثلاث حالات:
- أن يصله سهم وينطلق منه السهم الآخر، مثال ذلك
في التركيب
في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (1) و(2).
- أن ينطلق منه السهمان، مثال ذلك
في التركيب
في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (3) و (4).
- أن يصله السهمان، مثال ذلك
في التركيب
في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (5) و (6). يسمى الرأس في هذه الحالة نقطة تصادم (collider) وأيضا يسمى هذا التركيب (v-structure).
 في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (1) و(2).
في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (1) و(2). في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (3) و (4).
في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (3) و (4). في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (5) و (6). يسمى الرأس في هذه الحالة نقطة تصادم (collider) وأيضا يسمى هذا التركيب (v-structure).
في الشبكة المعطاة سابقاً والموضح أدناه في الشكلين (5) و (6). يسمى الرأس في هذه الحالة نقطة تصادم (collider) وأيضا يسمى هذا التركيب (v-structure).
بالنسبة للحالتين الأولى والثانية، فإنه في حالة أن قيمة المتغير في الرأس الفاصل ليست معروفة (لا نعرف المتغير هل يأخذ الحدث أو نقيضه) فإن المتغيرين اللذين يفصلهما هذا الرأس مرتبطان. فمثلاً في الرسم (1) في الصف الأول من الشكل أعلاه 




بالعودة إلى ما تمثله هذه المتغيرات، فيمكن قراءة هذه الجمل من الشبكة (أؤكد مرة أخرى أن الشبكة افتراضية وليست بالضرورة ممثلة للواقع. فقد تكون شبكة العلاقات في الواقع مغايرة):
- في حالة عدم معرفتي بمدى إتقان الطالب علم اللغة الدلالي، فإن معرفتي بمدى اجتهاد الطالب تفيدني في تكوين اعتقاد بمدى إتقان الطالب لعلم المنطق (أو العكس). أما في حالة معرفتي بمدى إتقان الطالب لعلم اللغة الدلالي، فإن معرفتي باجتهاد الطالب لا تفيدني في تكوين اعتقاد بكون الطالب متقن لعلم المنطق أم لا (أو العكس).
- ًفي حالة عدم معرفتي بكون الطالب لديه أعراضاً صحية أم لا، فإن معرفتي بمشاركة الطالب في الأنشطة اللاصفية من عدمها تفيدني في تكوين اعتقاد حول ما إذا كان الطالب مجتهد أم لا (أو العكس). أما في حالة معرفتي بكون الطالب لديه أعراضا صحية أو ليس لديه أية أعراض فتجعل من المعلومة التي تأتيني بخصوص مشاركته في الأنشطة اللاصفية غير مفيدة لتكوين اعتقاد بخصوص اجتهاد الطالب من عدمه (أو العكس).
بالنسبة للحالة الثالثة، نقطة التصادم، فهي عكس الحالتين السابقتين. فإنه في حالة عدم معرفة قيمة المتغير في نقطة التصادم 


لذا يمكن قراءة التالي:
- في حالة معرفتي بإمكانية الطالب على القيادة، فإن المعلومة التي تأتيني بخصوص إتقانه للعلوم الاجتماعية تفيدني في تكوين اعتقاد بخصوص مشاركته في الأنشطة اللاصفية (أو العكس). أما في حالة عدم معرفتي بإمكانية الطالب في القيادة فإن أي معلومة تأتيني بخصوص مشاركة الطالب في الأنشطة اللاصفية لا تفيدني في تكوين اعتقاد بخصوص إتقانه للمواد الاجتماعية.
يمكن فهم الحالة الثالثة كالتالي: إذا كانت المواد الاجتماعية والأنشطة اللاصفية تؤثر في مهارات القيادة، وعلمت أن الطالب لديه مهارات قيادية عالية مثلاً، فقد يكون اكتسبها من أحد المؤثرين أو من كليهما. فإن علمت أنه غير مشارك في الأنشطة اللاصفية فقد يتولد لدي اعتقاد بأنه اكتسب مهارات القيادة من خلال المواد الاجتماعية وبالتالي فإن المتغيرين مرتبطان. أما إذا كانت قيمة المتغير المتعلق بمهارات القيادة غير معروفة، فلا إتقان الطالب للمواد الاجتماعية يفيدني في تكوين اعتقاد بخصوص مشاركة الطالب في الأنشطة اللاصفية، ولا مشاركة الطالب في الأنشطة اللاصفية تفيدني في تكوين اعتقاد بخصوص إتقانه للمواد الاجتماعية.
يمكن تعميم الحالات أعلاه على أي متغيرين في الشبكة بغض النظر عن عدد الرؤوس التي تفصلهما، وذلك من خلال خاصية الــ d-separation (والتي سأشرحها الآن).
قراءة الارتباط والاستقلال من الشبكة بشكل عام
الآن بالإمكان شرح خاصية الـ d-separation والتي يمكن استخدامها لمعرفة ارتباط واستقلال أي متغيرين في الـ Bayesian Network بغض النظر عن المسافة بينهما.
بداية، يمكن تعريف سلالة رأس ما (Descendants of a vertex) في الـ Bayesian Network على أنه جميع الرؤوس التي يمكن الوصول إليها بطريق موجه يبدأ من هذا الرأس. فعلى سبيل المثال، في الشبكة أعلاه، سلالة 

لتكن المجموعة 


- في حالة وجود نقطة تصادم في هذا الطريق فإنها تنتمي للمجموعة
أو أن أحد أفراد سلالتها ينتمي للمجموعة
.
- لا يوجد محطة في هذا الطريق ليست نقطة تصادم و تنتمي للمجموعة

بالعودة إلى الشبكة السابقة، دع المجموعة التي نعرف قيم متغيراتها هي 





















يمكن الآن تعريف خاصية الـ d-separation (العزل) كالتالي:
مجموعة المتغيرات 


أي أنه بمعرفتنا بقيم المتغيرات في مجموعة ما

وبإمكانك معرفة استقلال وارتباط أي متغيرين آخرين من خلال فحص خاصية العزل بينهما.
استخدام الشبكة للتحليل والاستعلام
يستفاد من الـ Bayesian Network في الاستعلام عن احتمالية وقوع الأحداث وتحليل الأحوال التي وقعت بها بعض الأحداث. من أنواع الاستعلام:
- حساب احتمال أحداث معينة بعد معرفة أحداث أخرى. فعلى سبيل المثال، ما هو احتمال أن يتقن الطالب علم الجبر وتكون إمكانياته القيادية عالية إذا علمنا أنه مجتهد ولكنه غير متقن لعلم المنطق:

- ما هو الاحتمال الأكبر لقيم متغيرات معينة بمعرفة متغيرات أخرى. فعلى سبيل المثال، ما هو احتمال الأكبر لقيمة علم الجبر (متقن أم غير متقن) وقيمة القدرة القيادية (عالية أم منخفضة) إذا علمنا أنه مجتهد ولكنه غير متقن لعلم المنطق (يمكن فهم argmax على أنها تعيد لك القيم للمتغيرات المعرفة في أسفلها والتي تحقق أعلى قيمة للدالة المعطاة، أي هنا تعيد قيم المتغيرات التي تعطي أعلى قيمة احتمالية):

- معرفة الأحداث الأكثر احتمالاً والتي تفسر ظاهرة ما. على سبيل المثال، ماهي الأحداث الأكثر احتمالاً التي تفسر كون الطالب غير مجتهد ومتقن لعلم اللغة التركيبي:

السببية (Causality) والارتباط
تعتبر العلاقة السببية (Causal relationship) بين متغيرين علاقة ارتباط خاصة، حيث تكون قيم الأحداث لأحد هذين المتغيرين أسباباً لوقوع الأحداث التي يأخذها المتغير الآخر. ولكن ليست كل علاقة ارتباط بين متغيرين هي علاقة سببية. فقد يكون ارتباط حدثين ببعضهما نتيجة لسبب مشترك مجهول يسبب الحدثين معا. فعلى سبيل المثال، بالعودة إلى الشبكة السابقة، لنفترض أننا لا نعلم قيمة أي متغير في الشبكة. ففي هذه الحالة يعتبر المتغيران 

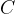

أيضاً من الأخطاء الشائعة اعتبار الـ Bayesian Network نموذجاً لعلاقات سببية حيث توجد الأسهم الموجهة والتي قد يعتبرها البعض روابط تنطلق من السبب إلى الأثر. وهذا ليس صحيحاً. فليس كل Bayesian Network تمثل علاقات سببية، بل هي تمثل توزيعاً احتمالياً قد يربط بين المسببات والآثار، وقد يكون غير ذلك. وللتوضيح، افترض أن لديك متغيران 


فلو أعطينا هاتين الصيغتين إلى شخصين مختلفين وطلبنا منهما أن ينمذجا الشبكة كل على حدة، فإن الشخص الأول سينمذجها كالتالي:
![]()
بينما الآخر سينمذجها كالتالي:
![]()
فإن تفسير الروابط المتجهة على أنها تربط السبب بالأثر، يجعلنا نستنتج من الرسم الأول أن
خاتمة
تعتبر النماذج الشبكية الاحتمالية موضوعا هاما من مواضيع الذكاء الاصطناعي وتعليم الآلة. وقد حاولت في هذه المقالة شرح المبادىء الأساسية التي تعتمد عليها مع شرح أساسيات أحد نماذجها وهو الــ Bayesian Network. وفي حالة ما إذا كان الموضوع غامضا للوهلة الأولى، فيمكن دراسته دراسة متأنية والتفكير في كثير من الظواهر الموجودة في عالمنا ومن ثم محاولة الربط بينها وبين المفاهيم المطروحة هنا. وفي حالة وجود أسئلة متعلقة بهذا الموضوع، يمكن طرحها وسأحاول الإجابة عليها بإذن الله.




شكرا دكتور وليد بحجم السماء وجزاك الله خير .
سؤالي بحكم تخصصك بالاحتمالات : هل هناك جوانب علمية متخصصة بنماذج الاحتمالات وليست على صلة بأي تخصص منطقي؟
السلام عليكم أخ عمر،
غالبية القرارات التي نتخذها في أي مجال لا يمكن أن نجزم بتبعاتها. وأيضا الظواهر نسبة كبيرة منها ليست محددة وفق المعطيات التي نعرفها، فتستخدم النماذج الاحتمالية في محاولة فهمها. لا أعرف مجالا علميا لا تدخل فيه نماذج الاحتمالات: المجال الطبي (تشخيص الامراض، البحث عن أدوية …)، اللغويات (نمذجة اللغة بطريقة احتمالية لمعرفة الكلمات الأكثر احتمالا للظهور في سياقات معينة مثلا)، الاقتصاد (توقع الأوضاع الاقتصادية بناء على معطيات معينة: الموارد، الدخل وغيرها) … وقس على ذلك المجالات الأخرى.
إذا كان سؤالك عن طريقة دراسة وعرض الاحتمالات، فأغلب المراجع التي قرأتها لا تعتمد الأسلوب المنطقي البحت (مثلا لا تستخدم الروابط المنطقية بالطريقة التي عرضتها في المقالة). بل تعتمد الأسلوب الرياضي الكمي، وغالبا تعرض الاحتمالات مع ما يسمى بــ “طرق العد” (Counting Techniques).
تحياتي أخ عمر.
جزاكم الله خيرًا دكتور وليد على هذا الجهد الرائع.
هل يمكن أن ترشح لنا مصادر تعليمية يمكن أن نبدأ منها دراسة النماذج الاحتمالية في إطار التعلم العميق؟
وإياك أخي أحمد.
لا أعلم حقيقة عن عمل يطرح النماذج الاحتمالية في إطار التعلم العميق.
بالنسبة للنماذج الاحتمالية جميعها (شبكية موجهة، شبكية غير موجهة، شبكية موجهة جزئيا)، فمن الصعب أن تغطى في مرجع واحد. بالنسبة للنماذج الاحتمالية الموجهة أو الــ Bayesian Networks فأنصح بكتابين للمبتدئين:
Adnan Darwiche, 2014. Modeling and Reasoning with Bayesian Networks, Cambridge University Press.
و
Nielsen, Thomas Dyhre, VERNER JENSEN, FINN, 2007. Bayesian Networks and Decision Graphs, Springer.
ماشاء الله تبارك الله. مقال علمي رائع يفتح الشهيه 🙂
الd-separation يمكن اختبارها بطريقه grahical حيث تعمل moralization ومن ثم triangulation للقراف وتشيك مثل هنا http://web.mit.edu/jmn/www/6.034/d-separation.pdf
اعتقد انها اسهل للطلاب وحقيقة دايماً اتبعها بدل التعقيد اللي حاصل بتعريفات الd-separation، هل توافقني الراي؟ جزاك الله خير وكثر من أمثالك.
حياك الله أخي عيسى،
بالنسبة للــ d-separation فهي خاصية معرفة فقط على النماذج الموجهة و الــ d هنا اختصار لكلمة directed. بالإمكان معرفة استقلال متغيرين في الشبكات الموجهة عن طريق تحويل هذه الشبكة إلى شبكة غير موجهة (Markov Network/Markov Random Field) ومن ثم استخدام خاصية الــ Global Markov Property في معرفة الاستقلال في هذا النوع من الشبكات. وهذه هي الطريقة المشروحة بشكل مختصر في الرابط (ولكن الملف في الرابط ذكر الــ d-separation ثم ذكر هذه الطريقة ولم يوضح أن هذه ليست الــ d-separation). أثناء تحويل الشبكة الموجهة إلى شبكة غير موجهة: تحذف اتجاهات الأسهم ومن ثم يتم عمل الــ Moralisation/Moralization (تشريع العلاقة) وذلك “بتزويج” الأباء الذين ليس بينهم روابط (كما هو الحال في N و Z في الشبكة الموجودة في المقال) حتى يتم التخلص من نقط التصادم. عندها يصبح أي متغيرين منعزلين عن بعضها إذا كان لا يوجد طريق بينهما لا يمر بمتغير معطى وهذه هي خاصية الــ Global Markov Property بشكل مختصر.
الفرق هنا أن الــ d-separation ظهرت في دراسة الشبكات الموجهة، والــ Markov Properties ظهرت في دراسة الشبكات الغير موجهة. والتحويل من الأولى إلى الثانية وارد، أما العكس ففيه اشكالات.
بالنسبة للــ Triangulation فتستخدم في بعض خرازميات الاستنتاج (الــ inference).
تحياتي أخ عيسى.
———————–
ملاحظة: أو التنبيه على خطأ لغوي (قد يغير في المعنى) ورد في المقال وظهر في اقتباس على حساب الموقع في تويتر وهو:
“ليست كل علاقة ارتباط بين متغيرين هي علاقة سببية. فقد يكون ارتباط حدثين ببعضهما نتيجة لسبب مشترك مجهول يسبب الحدثان معا”.
الحدثان = الحدثين.
“بالنسبة للــ d-separation فهي خاصية معرفة فقط على النماذج الموجهة و الــ d هنا اختصار لكلمة directed. بالإمكان معرفة استقلال متغيرين في الشبكات الموجهة عن طريق تحويل هذه الشبكة إلى شبكة غير موجهة (Markov Network/Markov Random Field) ومن ثم استخدام خاصية الــ Global Markov Property في معرفة الاستقلال في هذا النوع من الشبكات. ”
أود أيضا أن أضيف أن هذه الجملة لا تؤخذ بالعموم على كل الحالات. ليست كل حالات الاستقلال الموجودة في الشبكات الموجهة يمكن معرفتها بتحويل الشبكة إلى شبكة غير موجهة. خذ مثلا نقطة التصادم عندما تكون غير معطاة:
1- ففي الشبكة الموجهة يكون الآباء مستقلين.
2- في الشبكات الغير موجهة، بعد تزويج الآباء، يكونون غير مستقلين.
ولكن في حالات كثيرة يمكن قراءة نفس علاقات الارتباط والاستقلال من الشبكتين.
تحيتي.